7. Kategorizazioa: Baliabide-klaseak eta -motak deskribatzea
Robert J. Glushko, Rachelle Annechino, Jess Hemerly, Robyn Perry, Longhao Wang
7.5 Kategoriak inplementatzea
Kategoriak eraikuntza kontzeptualak dira, eta normalean era ikusezinean baliatzen ditugu, haietaz hitz egitean edo pentsatzean. Sukaldea edo armairua antolatzen dugunean apalak eta tiraderak erabiliz, kokapen eta edukiontzi fisikoak gure kategoria-sistema pertsonalaren inplementazio ikusgaiak dira, baina ez dira kategoriak beren horretan. Kategoria-diseinuaren eta -inplementazioaren arteko bereizkuntza agerikoa da honako egoera hauetan: liburutegietan edo janari-dendetan seinaleei edo etiketei jarraitzen diegunean, gauzak topatze aldera; bilaketak egiten ditugunean produktu-katalogo batean edo konpainiako langileen direktorio batean; edo gobernuak, zerga-aitorpeneko informazioa baliatuz, datu ekonomikoen sortak biltzen dituenean. Jendeak sortu zituen kategoria instituzional horiek, baliabideak kategorietan sailkatu aurretik.
Kategoriak sortzearen eta inplementatzearen arteko bereizketak galdera hau dakarkigu: nola inplementatu daitezke kategoria-sistemak? Kategorien inplementazioari dagokionez, ez dugu horren zentzu literala azalduko, hau da, ez dugu aipatuko baliabideen antolaketarako sistema fisikoen zein software sistemen eraikuntza. Aitzitik, maila gorenago batetik erreparatuko diogu kontuari, eta aztertuko du zer inplementazio-arazo konpondu behar den 7. 3 atalean aipaturiko kategoria-motei dagokienean; ondoren, baliabideak egoki esleitzeko logika esplikatuko dugu.
7.5.1 Enumerazio-kategoriak inplementatzea
Erraza da enumerazio bidezko kategoriak inplementatzea. Sortako kideek edo lege-balioek definitzen dute kategoria, eta item bat kategoria horretako kidea den jakiteko, sortan bilatzea besterik ez dago. Kategoria-definizioen enumerazioak maiz erabiltzen dira beherantz jotzen duten menuetan eta formularioetan. Munduko herrialde guztien zerrenda bat daukazu, eta behera egiten duzu saguarekin, bidalketa-helbide batean ipini nahi duzun herrialdea topatu arte; edozein hautatzen duzula ere, baliozko herrialde-izen bat izango da, zeren zerrenda finkoa baita harik eta herrialde berri bat sortzen den arte. Halaber, enumerazio-kategoriak erabil daitezke taula asoziatiboetan (hash taulak ere esaten zaie). Datuen egitura horrekin, sortako baliokidetza egiaztatzeko probak are eraginkorragoak dira bilaketa baino, denbora berdina behar baitute edozein neurritako sortak aztertzeko (ikus 9.2.1 atala: Egitura-motak).
7.5.2 Ezaugarri bidez zehazturiko kategoriak inplementatzea
Ezaugarri bidez zehazturiko kategorien inplementazio kontzeptualki sinpleenak eta zuzenenak kategorien ikuspegi klasikoari heltzen dio, ezaugarri beharrezkoetan eta nahikoetan oinarritzen denari, alegia. Halako kategoriak, batetik, preskriptiboak dira, eta, bestetik, muga argiak eta zehatzak dituzte; ondorioz, itemen sailkapena objektiboa da, baldintza zehatz batzuen araberakoa, eta balioztatzearen nozio argiki zehaztu bat ahalbidetzen du, zeinaren bidez ebazten baita ea kasu bat kategoriako kidea den ala ez. Itemak sailkatu ala ez erabakitzeko, probak egiten zaizkie, eta hala zehazten da ea behar diren ezaugarriak eta ezaugarri-balioak dituzten. Proba horiek, bestalde, arau gisa adierazi daitezke.
- X kasuak P ezaugarria baldin badauka, orduan Y kategorian egongo da.
- San Frantzisko hirian etxe bat erosteko hipoteka-kreditu batek 625.000 dolar baino gehiago balio badu, orduan kreditu «erraldoitzat» joko du AEBko Etxeen Ikuskaritza Federalak, erakunde horrek ezarritako mugak gainditzen baititu.
- Zenbaki bat zenbaki lehen gisa har dadin, bi arau bete behar ditu: 1 baino handiagoa izan behar du, eta, 1 zenbakiaz eta bere buruaz aparte, ez du beste zatitzailerik eduki behar.
Honek ez du esan nahi ezaugarrien probak egitea erraza suertatzen denik beti; izan ere, gerta liteke, balioztatzea egiteko, ekipamendu edo kalkulu berezien premia izatea, eta ezaugarri-proben kostua edo eraginkortasuna ez da berdina izango beti. Baina, behin probaren emaitzak jasota, erantzuna guztiz argia da, anbiguotasun-izpirik gabe. Bietako bat: itema kategoriako kidea da, edo ez da.
Ordena jakin batean egindako ezaugarri-proben sekuentzia batek zehazten du kategoria hierarkikoen sistema. Erabaki-zuhaitzak dira hainbat mailatako kategoria-sistemak inplementatzeko modurik naturalena. Erabaki-zuhaitz sinpleak algoritmoak dira, zeinak erabaki bat zehazten baitute, ezaugarri-proba edo proba logikoen sekuentzia bat eginez. Demagun bankuek arauetan oinarrituriko ikuspegi sekuentzial bat baliatzen dutela pertsona bati hipoteka-kreditua eman edo ez erabakitzeko.
- Mailegu-eskatzailearen urteroko diru-sarrerak 100.000 dolar baino gehiago badira, eta hipoteka-kredituaren hileroko kuota hileroko diru-sarreren % 25 baino gutxiago bada, onartu mailegu-eskaera.
- Osterantzean, errefusatu mailegu-eskaera.
Erabaki-zuhaitz sinple hori 7.1 marrazkian erakutsi dugu: Arauetan oinarrituriko erabaki-zuhaitza. Zuhaitzean argi adierazten da zer arau erabiltzen dituen bankuak mailegu eskaerak «Onartu» edo «Errefusatu» kategorietan sailkatzeko. Erraza da erabaki-zuhaitzak interpretatzea; horregatik, ohiko formalismoa dira sailkapen-ereduak inplementatzeko orduan.
7.1 marrazkia: Arauetan oinarrituriko erabaki-zuhaitza
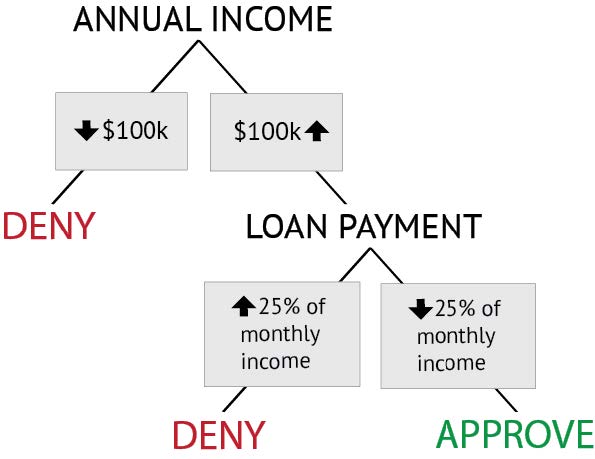
Erabaki-zuhaitz sinple honetan, bi proba egiten dira, hurrenkera zehatz batean, bi faktore hauek kontuan hartuta: lehenik, mailegu-eskatzailearen urteko diru-sarrerak; bigarrenik, hileroko sarreren zer ehunekok osatzen duen maileguaren hileroko kuota. Bi proba horien arabera sailkatzen dira eskatzaileak «errefusatu» edo «onartu» kategorietan.
Edonola ere, kategorien inplementazioa interpretagarria izateko, ezinbestekoa da kategoriaren definizioan eta inplementazioan erabiltzen diren ezaugarriak eta probak ulergarriak izatea. Hizkuntza naturala berez da anbiguoa; hortaz, ez da formatu egokiena kategoria instituzional formalki zehaztuetarako. Kategoriak hizkuntza naturalaren bitartez zehazten badira, baliteke ez-osoak, koherentziarik gabeak eta anbiguoak izatea, hitzek hainbat esanahi izaten dituztelako sarri. Maileguak ebaluatzeko bankuak erabiltzen duen prozedura horrela inplementatuz gero, zaila izango litzateke hori era fidagarrian interpretatzea:
- Mailegu-eskatzailea aberatsa baldin bada, eta hileroko kuota erraz ordain badezake, mailegu-eskaera onartuko da.
Erraz interpretatzeko modukoak direla ziurtatzeko, erabaki-zuhaitzak hiztegi kontrolatuekin eta sintaxi mugatuarekin idazten dira –«idazketa sinplifikatua» edo «negozio-arauak» deritzen sistemekin–.
Bestalde, propietateetan oinarrituriko kategoriak zehatz-mehatz adierazi nahi direnean, badago modu anbizio handikoago bat hori egiteko: hizkuntza artifiziala erabiltzea. Hizkuntza artifizialek zehatz-mehatz adierazten dituzte ideiak: ideia konplexuak adierazteko, termino edo sinbolo berriak txertatzen dituzte, eta, horrez gainera, mekanismo sintaktikoak ere baliatzen dituzte, termino horiek uztartzeko eta erabiltzeko. Hizkuntza artifizial ezagunak dira, besteak beste: notazio matematikoa, programazio-hizkuntzak, dokumentu-kasu baliozkoak zehazten dituzten eskema-hizkuntzak (ikus 9.2.3.1 atala) eta bilaketa- eta hautaketa-patroiak zehazten dituzten adierazpen arautuak (ikus 9.2.3.2 atala). Ezbairik gabe, errazagoa da Pitagorasen Teorema azaltzea eta ulertzea modu efizientean adierazten denean, hau da, «H2 = A2 + B2» formularen bidez, ezen ez hizkuntza naturaleko adierazmolde hitzontziago batean: «Hiruki baten angelua halakoa bada non hirukiaren bi alde elkarren perpendikularrak baitira, angelu zuzenaren beste aldean dagoen aldearen luzeraren berretura beste bi aldeen luzeraren berreturaren baturaren parekoa izango da».
Filosofian eta zientzian barra-barra erabili izan dira hizkuntza artifizialak, kategoriak zehazteko. (Ikus koadro gehigarria: Deskribapenerako eta sailkapenerako hizkuntza artifizialak). Alabaina, kategoria-sistema instituzionalen gehiengoa hizkuntza naturalaren bidez adierazten da oraindik ere, anbiguotasunak anbiguotasun, jendeak hizkuntza artifizialak baino hobeto ulertzen dituelako era naturalean ikasitako hizkuntzak. Batzuetan, nahita egiten da gainera, legeetan gauzatzen diren kategoria instituzionalak auzitegietan gara daitezen uzteko, eta aurrerakuntza teknologikoetara egokitzeko. Datu-eskemek, Dokumentu Moten Espektroko (ikus 4.2.1 atala) mutur transakzionaleko dokumentu-motetan eta datu-baseetan dauden datu-entitateak, elementuak, identifikatzaileak, atributuak eta harremanak zehazten dituztenek, informazioaren antolaketa-sistemak diseinatzeko, garatzeko eta mantentzeko behar diren kategorien inplementazioa gauzatzen dute. Datu-eskemek, normalean, zurrunki zehazten dituzte baliabide-kategoriak.
Objektuetara bideraturiko programazio-hizkuntzetan, klaseak ere eskemak dira, eta objektuak sortzeko txantiloi gisa balio dute. Programazio-hizkuntzetako klaseak, beraz, datu-baseko kasuen egitura zehazten duen eskemaren modukoak dira, klase-definizioak zehazten baitu nola eraikitzen diren klase horretako kasuak datu-motei eta balizko balioei dagokienean. Programazio-klaseek, gainera, objektu-kide bateko datuetara irits daitekeen zehaztu dezakete, eta, hala bada, nola egin daitekeen.
Dokumentu-mota transakzionalak, maiz, prozesu automatizatuen bidez ekoizten eta kontsumitzen dira, beraz, kategoria klasiko gisa definitu ditzakegu modu preskriptiboan; horien kontrakarrean, dokumentu-mota narratiboak deskriptiboak izan ohi dira. Liburu bat eleberri bat dela esaten dugunean, ez ditugu oinarritzat hartzen ezaugarri eta eduki-mota jakin batzuk. Aitzitik, nobela tipikoei eta horien ezaugarri bereizgarriei buruzko halako nozio bat dugu, baina eleberritzat hartzen diren gauzetako batzuk oso urruti daude egitura eta eduki tipikotik.
Haatik, batzuetan, dokumentu-eskemak erabiliz inplementatu daitezke dokumentu-mota narratiboen kategoriak, muga gutxi batzuk ezarriz egiturari eta edukiari dagokionez. Erosketa-agindu bati dagokion eskema preskriptiboa izango da oso: adierazpen aratuak erabiltzen ditu, baita datuak ere, eta ordena jakin batean egon behar duten elementuen balioa balioztatzeko kode-zerrenda zenbakituak. Kontrara, dokumentu-mota narratibo baten eskemaren kasuan, hautazko aukera ugari egongo lirateke, malgua izango litzateke ordenari dagokionez, eta testua bakarrik agertuko litzateke eskemako ataletan, paragrafoetan eta goiburuetan. Dokumentu-eskemak, malgu-malguak izanda ere, erabilgarriak izan daitezke edukiaren kudeaketa, berrerabilera eta formatua efizienteagoak izan daitezen.
Deskribapenerako eta sailkapenerako hizkuntza artifizialak
Errege Elkarte Britainiarraren sortzaileetako bat izan zen John Wilkins. 1668. urtean, An Essay towards a Real Character and a Philosophical Language kaleratu zuen, zeinean hizkuntza artifizial bat proposatu baitzuen, jakintzaren taxonomia unibertsal bat deskribatzeko; hizkuntza horretan, sinboloen konposizioa erabiltzen zen kategoria-hierarkiako posizioak zehazteko. Goi-mailako berrogei genero-kategoria zeuden; ondoren, kategoria horietako bakoitza zatitzen zen, generoen baitako ezberdintasunak adierazteko; gero, espezietan zatitzen ziren. Genero bakoitza monosilabo bat zen, bi letraz osatua; ezberdintasun bakoitzak, berriz, kontsonante bat gehitzen zuen, eta espezie bakoitzak bokal bat.
Hizkuntza artifizial horretan, kategoria-izenaren konposizioak erakusten du, zuzenean, zein den kategoriaren esanahia. Adibidez, zi terminoak piztien generoa adierazten du: hortaz, zit terminoak «txakurren gisako piztia harraparia» adieraziko luke; zid, berriz, zera litzateke: «apatx biko piztia». Laugarren karaktere bat erantsiz gero, espezieari dagokiona, adibidez a, hauek sortuko lirateke: zita (txakurra) eta zida (ardia).
Jorge Luis Borges idazleak, «El idioma analítico de John Wilkins» narrazioan, azpimarratzen du ezen Wilkinsen hizkuntzak «anbiguotasun, errepikapen eta gabezia» ugari dituela, eta parodia gisa aurkezten du «Jakintza Onberaren Zeruetako Inperio» irudimenezko bat:
-
Haren orrialde urrunekoetan idatzirik datza animaliak honako sail hauetan banatzen direla: a) enperadorearen jabetzakoak, b) baltsamatuak, c) bezatuak, d) urdeak, e) uhandreak, f) miragarriak, g) txakur deslaiak, h) sailkapen honetan bilduak, i) ero moduan astintzen direnak, j) ezin konta ahal, k) gamelu-ileko pintzel fin-fin batekin marraztuak, l) eta abar, m) lorontzi bat hautsi berri dutenak, n) urrutitik begiratuz gero euliak diruditenak.
Wilkinsek izen batzuk asmatu zituen, zeinek nolabaiteko esanahia izan baitzezaketen beren horretan, sistema ezagutzen zutenentzat behinik behin, eta hori goretsi egiten du Borgesek, baina zera eransten du: «argi dago ez dagoela Unibertsoaren sailkapenik, arbitrarioa eta aieruz betea ez denik».
7.5.3 Probabilitatearen eta antzekotasunaren bidez definituriko kategoriak inplementatzea
Kategoria asko ezin dira zehaztu propietate beharrezkoen bidez; aitzitik, probabilitatearen arabera zehazten dira, kontuan hartuz baliabideek zer ezaugarri komun izango dituzten probableki. Har dezagun, adibide baterako, «lagun» kategoria. Seguru asko, lagun asko dituzula uste izango duzu, baina badaude aspaldiko lagunak, eskolako lagunak, lantokiko lagunak, gimnasioan baizik ikusten ez dituzun lagunak eta zure gurasoen lagunak. Lagun-mota horietako bakoitzak propietate komunen multzo ezberdin bat osatzen du. Pertsona bati buruz aritzean, balizko lagun edo maitale gisa deskribatzen badizute, zer-nolako zehaztasunez aurreikusi dezakezu ea pertsona hori lagun bihurtuko den etorkizunean?
Zaila gerta daiteke probabilitate-kategoriak zehaztea eta erabiltzea, zaila izan baitaiteke eremu bateko kasuen multzoetan agertzen diren ezaugarrien arteko korrelazio eta probabilitateak gogoan gordetzea. Are gehiago, ikasi beharreko kategorian kide asko baldin badaude, ikasten duzun laginak zeharo taxutuko du zer ikasten duzun. Adibidez, balizko maitale onargarri bat zein den zehazteari dagokionez, biztanleria homogeneo samarreko landa-eremu isolatu batean hazitako jendeak iritzi aurreikusgarriagoak izango ditu biztanleria eta aniztasun handiko hiriguneetan hazitako jendeak baino.
Maila orokorrago batean, baliabide aktiboen edo aldakorren eremu bat antolatzen ari bazara, edo eremu horretako propietateen probabilitate-neurketak aldatzen eta bat etortzen badira, hautatzen duzun laginak eragin handia izango du sailkapenerako eta aurreikuspenerako ereduen zehaztasunean. The Signal and the Noise lanean, Nate Silver estatistikariak azaltzen du aurreikuspen nabarmen askok huts egin zutela, laginak hartzeko teknika kaskarren ondorioz. Ohiko akats bat izan da leiho historiko laburregia erabiltzea prestakuntzari dagokion datu-sorta osatzeko; sarritan, beste ohiko akats baten ondorioa izaten da hori: datu berrietan gehiegi oinarritzea, halako gehiago dagoelako eskura. Esaterako, etxe-prezioen kolapsoak eragindako 2008ko finantza-krisia dela-eta, honela azal daiteke zer gertatu zen, hein batean behintzat: mailegu-emaileek, maileguen betearazpenak aurreikusteko, 1980-2005 bitarteko datuak erabili zituzten; garai hartan, etxe-prezioek igotzera egiten zuten. Ondorioz, maileguen betearazpenak azkar bai azkar hazi zirenean, emaitzak «laginetik kanpokoak» ziren, eta, hasiera batean, oker interpretatu ziren; horregatik, krisiarekiko erantzunak berandutu ziren.
7.5.3.1 Probabilitatezko erabaki-zuhaitzak
7.5.2 atalean erakutsi dizuegu nola erabil daitekeen arauetan oinarrituriko erabaki-zuhaitz bat, propietateetan oinarrituriko sailkapen zorrotz bat bat inplementatze aldera: adibide horretan, banku batek «urteko diru-sarrerak» eta «hileroko mailegu-kuota» ezaugarriei dagozkion probak egiten zituen, eta horren arabera onartzen edo errefusatzen zituen mailegu-eskatzaileak. Adibide hori egokituz, erabaki-zuhaitz probabilistikoak zertan diren argitu dezakegu, zeinak egokiagoak baitira kategorietako-kidetza absolutua ez baizik probabilistikoa ezartzen duten kategoriak inplementatzeko.
Maileguak emateko baldintza malguagoak ezartzen dituzten bankuek etekin handiagoak lor ditzakete, izan ere, maileguak ematen baitizkiote banku zorrotzago batek onartuko ez lituzkeen bezeroei, zeinak gai baitira, hala ere, maileguaren kuotak ordaintzeko. Halako bankuek ez dituzte muga kontserbadore eta finkoak ezartzen diru-sarrerei eta hileroko kuotei dagokionean; aitzitik, propietate gehiago hartzen dituzte aintzat, eta mailegu-eskaerei probabilitatearen ikuspegitik erreparatzen diote. Halako bankuen ustean, mailegua ordaintzeko moduan dauden eskatzaile guztiek ez dute itxura berdin-berdina; «urteko diru-sarrerek» eta «hileroko mailegu-kuotak» ezaugarri inportanteak izaten jarraitzen dute, baina beste faktore batzuk ere lagungarriak suerta daitezke aurreikuspenak egiteko; hala, mailegu-eskaera bat onartzeko, ezaugarri-balioen konfigurazio bat baino gehiago har daiteke egokitzat.
Eskatzaile batek mailegua itzuliko duen edo ez aurreikusteko, zer ezaugarri dira egokienak? Aukera bakoitzari % 50eko probabilitatea aurreikusten dioten ezaugarriak ez dira lagungarriak izango, ez baitute oinarririk ematen bankuak aukera baten edo bestearen alde egin dezan; aitzitik, ezaugarri batek bi multzotan banatzen baditu eskatzaileak, eta multzoetako bakoitzak oso probabilitate ezberdinak baditu maileguaren itzulketari eta ez-ordainketari dagokionez, erabilgarria izango da, oso, mailegua eman edo ez erabakitzeko garaian.
Datuetan oinarritzen diren bankuek, maileguen itzulketari eta ez-ordainketari buruzko datu historikoak baliatuz, algoritmoak prestatzen eta erabaki-zuhaitzak sortzen dituzte, mailegu-eskatzaileak behin eta berriro sailkatuz aurreikuspen ezberdinak dakartzaten azpi-sortatan. Mailegua itzultzeko probabilitate handia duten eskatzaileen azpi-sortak onartuko dira; besteei, ordea, ez zaie mailegua emango. Banaketa bakoitza egiteko ezaugarri-proba hautatze aldera, besteak beste, «informazio-irabazia» kalkulatzearen metodoa erabiltzen da. Neurri horrek zehazten du zer mailatan biltzen duen azpi-sorta bakoitzak multzo «puru bat», zeinean eskatzaile bakoitza sailkatzen baita, seguru asko mailegua itzuliko duen pertsona gisa edo seguru asko mailegua ordainduko ez duen pertsona gisa.
Esate baterako, errepara diezaiogun, 7.2 marrazkiari: Datu historikoak: Maileguen ordainketa, interes-ratioan oinarrituta; irudi horretan erakusten da itzuli ez diren maileguen harira bankuak dituen datu historikoen errepresentazio sinplifikatu bat. Koadroan, itzulitako mailegua «o» batekin markatuta daude; ordaindu ez direnak, berriz, «x» batekin. Ba al dago mailegu guztiak bi azpi-sorta «puru»tan banatzen dituen interes-ratiorik –hau da, «o» maileguak bakarrik biltzen dituen azpi-sorta bat eta «x» maileguak bakarrik biltzen dituen beste azpi-sorta bat sortzen duenik–?
7.2 marrazkia. Datu historikoak: Maileguen ordainketa, interes-ratioan oinarrituta
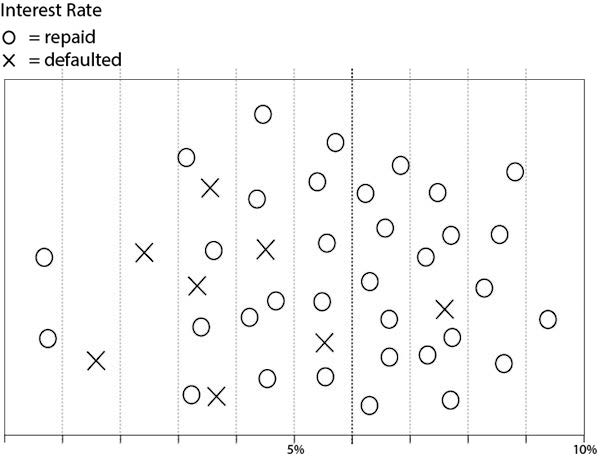
«o» sinboloak adierazten du zer mailegu itzuli diren; «x» sinboloak, berriz, zeintzuk ez diren itzuli. Maileguak banatu nahi badira ordainketa-emaitza ezberdinak dakartzaten bi azpi-sortatan % 6ko interes-ratioa da egokiena (marra beltz ilunago batek markatzen du ratio hori).
Ikus dezakezuen moduan, ez dago maileguak bi azpi-sorta purutan banatzen dituen interes-ratiorik. Hortaz, beste hau egitea komeni da: maileguak bestelako interes-ratioren baten bidez banatzea, mailegua itzuli ez zuten pertsonen proportzio ahalik eta ezberdinena egon dadin lerroaren alde batean eta bestean.
Mailegua itzuli zutenak eta ez zutenak ahalik hobekien banatzeko, banaketa-lerroa % 6ko interes-ratioan jartzea da egokiena. Dirua % 6ko interesarekin edo interes handiagoarekin mailegatu zuten gehienek mailegua itzuli zuten; interes baxuagoko maileguak hartu zituztenek, berriz, probabilitate handiagoa izan zuten mailegua ez itzultzeko. Kalkulu horrek ez dirudi oso zentzuzkoa, beste faktore honen berri izan ezean: interes baxuagoko ratioa zuten maileguek ratio aldakorra zuten, zeina igo egin baitzen urte gutxi batzuen buruan; ondorioz, hileroko kuotak nabarmen hazi ziren. Mailegatzaile zuhurragoek, ordea, nahiago zuten interes-ratio handiagoak ordaindu, betiere finkoak baldin baziren; horrela, hileroko kuotak ez ziren tupustean handituko.
7.3 marrazkia. Erabaki-zuhaitz probabilistikoa
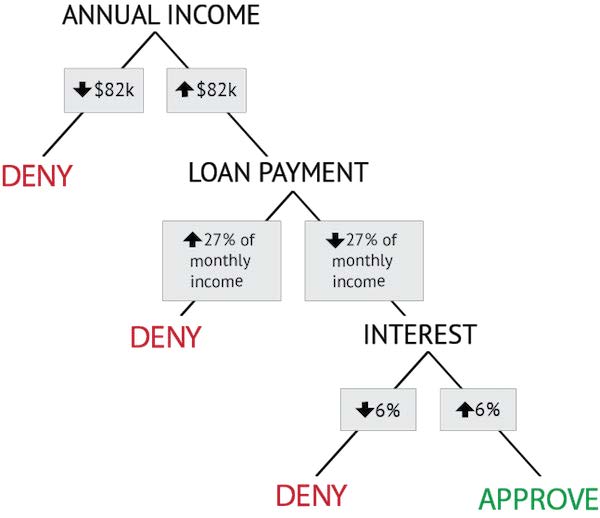
Erabaki-zuhaitz probabilistiko honetan, ezaugarri-proben sekuentziak eta proba bakoitzeko atalase-balioek bi kategoriatan banatzen dituzte mailegu-eskatzaileak; kategoria batek besteak baino probabilitate handiagoa izango du mailegua onartua izan dadin.
Datu-sorta historikoko atributu guztiekin egiten da kalkulu hau, jakite aldera zer ezaugarri den egokiena mailegu-eskatzaileak bi kategoriatan banatzeko: mailegua itzuliko dutenak eta itzuliko ez dutenak. Bai atributuak bai erabakia zehazten duen balioa ordenatu daitezke, 7.5.2 atalean ikusi dugunaren antzeko erabaki-zuhaitz osatzeko. Gure kasu hipotetiko honetan, ezaugarriak probatzeko ordena onena hauxe da: Diru Sarrerak, Hileroko Kuota eta Interes Ratioa, 7. 3 marrazkian erakutsi bezalaxe –Erabaki-zuhaitz probabilistikoa–. Azken emaitza arau-sorta bat izango da; hala ere, zuhaitzeko erabaki bakoitzaren atzean datu historikoetan oinarrituriko probabilitateak daude, zehatzago aurreikusi dezaketenak ea eskatzaileak mailegua itzuliko duen edo ez. Hortaz, ausazko muga batzuk ezarri beharrean (100.000 dolarreko diru-sarrerak urtean eta mailegu-kuoten % 25 hilean), bankuak maileguak eskaini ahal dizkie diru-sarrera apalagoak dituzten pertsonei, eta horri etekina atera, bankuak bai baitaki, datu historikoei esker, 82.000 dolarrerako diru-sarrerak urtean eta kuotaren % 27 hilean direla erabaki-puntu optimoak. Ondoren, interes-ratioa ere hartzen da aintzat, proba gehigarri bat, ziurtatu nahi baita jendea kuotak ordaintzeko gai izango dela baita ratioak hazten badira ere.
7.5.3.2 Naif Bayes sailkatzaileak
Kategoria probabilistikoen sailkapena inplementatzeko beste hurbilketa ohiko bat da Naif Bayes deritzona. Bayesen Teorema erabiltzen da jakite aldera zer garrantzia duen ezaugarri jakin batek sailkapen egokiari dagokionez. Bayesen Teoreman zentzu komuneko ideia batzuk mamitzen dira:
- Hipotesi bat edo aurretiazko sinesmen bat badaukazu ezaugarri baten eta sailkapenaren artean dagoen harremanaz, uste horrekin bat datozen froga berriek zure konfiantza areagotu behar lukete.
- Froga kontraesankorrek, ostera, uste horretan duzun konfiantza murriztu behar lukete.
- Gertakari jakin baten oinarrizko ratioa txikia baldin bada, ez zaitez horretaz ahaztu aurreikuspen bat egiten duzunean kasu berri baten inguruan edo kasu berri bat sailkatzen duzunean. Ohikoa izaten da informazio berriak gehiegizko eragina izatea.
Orain, ideia horiek adieraz ditzakegu, ikaskuntza nola gertatzen den dioten kalkuluen bitartez. A sailkapenari eta B ezaugarriari dagokionez, Bayesen Teoremak zera dio:
-
P (A ⎢B) = P (B ⎢A) P(A) / P(B)
Ekuazioaren ezkerreko aldea kalkulatu nahi genuke, P (A ⎢B), baina ezin dugu zuzenean neurtu: jakin nahi dugu zenbateko probabilitatea dagoen, B ezaugarria duen item edo behaketa bati dagokionez, A sailkapena egokia izateko. Probabilitate baldintzazkoa edo ostekoa esaten zaio honi, B ezaugarriaren froga ikusi ondoren kalkulatzen delako.
P (A ⎢B) probabilitateak adierazten du A gisa egoki sailkaturiko item guztiek dutela B ezaugarria. Probabilitate-funtzioa esaten zaio honi.
P(A) eta P(B), ordea, Aren eta Bren probabilitate independenteak edo aurretiazkoak dira: itemen zer proportzio sailkatzen da A gisa? Zenbat aldiz agertzen da B ezaugarria item-sorta horietako batzuetan?
Orain, Bayesen Teorema aplikatuko dugu, mezu elektronikoetako spam-filtroa inplementatzeko helburuarekin. Mezuak bi multzotan sailkatu dira: SPAM eta HAM (hots, spam ez direnak). Lehen multzoko mezuak Spam karpetara bideratuko dira; besteak, berriz, mezuen sarrera-ontzira.
- Ezaugarriak hautatu. Ezaugarri-multzo batekin hasiko gara; ezaugarri batzuk, mezuaren metadatuei dagozkie –bidaltzailearen helbide elektronikoa eta hartzaile-kopurua, adibidez–, eta beste ezaugarri batzuk, berriz, mezuaren edukiari. Mezuetan agertzen diren hitzak banaka har daitezke, bakoitza ezaugarri bat balitz bezala.
- Prestakuntza-datuak bildu. Mezu elektroniko batzuk bildu, SPAM eta HAM gisa egoki sailkatuak izan direnak. Etiketaturiko kasu horiek osatzen dute prestakuntza-sorta.
- Aztertu prestakuntza-datuak: Zer ezaugarri du mezu bakoitzak? Zer mezu sailkatu da SPAM gisa? SPAM gisa sailkaturiko mezuek ezaugarri jakin bat daukate? (Horra hor Bayes ekuazioko eskuinaldeko hiru probabilitateak).
- Ikasi. Baldintzazko probabilitatea (Bayes ekuazioko ezkerreko aldea) berriro kalkulatuko da, ezaugarri bakoitzaren aurreikuspen-balioa egokituz. Batera hartuz gero, ezaugarri guztiek ahalmena dute orain mezu gehienak sailkatzeko prestakuntza-sortan zegozkien kategorietan.
- Sailkatu. Sailkatzaile prestatua gertu dago mezu kategorizatu gabeak sailkatzeko SPAM eta HAM kategorietan.
- Hobetu. Sailkatzailearen zehaztasuna hobetu daiteke, baldin eta erabiltzaileak feedbacka ematen baldin badio, SPAM mezuak HAM gisa birsailkatuz, eta alderantziz. Ikaskuntza ahalik eraginkorrena izan dadin, algoritmoak «ikaskuntza aktiboko» teknikak erabili behar ditu, prestakuntza-datuak bere kasa aukeratzeko, eta mezu bat non sailkatu ziur ez dagoenean soilik eskatu behar du erabiltzailearen iritzia. Adibidez, algoritmoak seguru samar jakin dezake «droga merkeak» gaia duen mezu batek SPAM izan behar duela, baina mezuaren bidaltzailea, ordea, hartzailearekin urte luzez mezuak trukatu dituen bat baldin bada, algoritmoak erabiltzaileari galdetuko dio ea sailkapena egokia den ala ez.
Baldintzazko probabilitatea kalkulatzea, Bayesen Teorema erabiliz
Zure liburu-sorta pertsonalean, liburuen % 60 fikziozkoak dira, eta % 40, berriz, ez-fikziozkoak. Fikziozko liburu guztiak formatu elektronikoan daude; ez-fikziozkoei dagokienean berriz, bietatik dago: elektronikoak eta fisikoak, erdi eta erdi. Ausaz liburu bat hautatzen baldin baduzu, eta elektroniko baldin bada, zer probabilitate dago liburu hori ez-fikziozkoa izateko?
Bayesen Teoremak zera dio:
-
P (ez-fikzioa ⏐ elektronikoa) = P (elektronikoa ⏐ ez-fikzioa) x P (ez-fikzioa) / P (elektronikoa)
Bestalde, honako hau dakigu:
-
P (elektronikoa ⏐ ez-fikzioa) = .5 eta P (ez-fikzioa) = .4
P (elektronikoa) kalkulatzeko, zera egingo dugu: probabilitate osoaren legea erabiliz, liburu elektroniko baten laginak hartzeko dauden modu guztien probabilitate uztartua kalkulatuko dugu. Adibide honetan, bi modu daude:
-
P (elektronikoa) = P (elektronikoa ⏐ ez-fikzioa) x P (ez-fikzioa) + P (elektronikoa ⏐ fikzioa) x P (fikzioa) = (.5 x .4) + (1x .6) = .8
Hortaz: P (ez-fikzioa ⏐ elektronikoa) = (.5 x .4) / .8 = .25
7.5.3.3 Taldekatze bidez sorturiko kategoriak
Aurreko bi ataletan, zera azaldu dugu: nola inplementatzen dituzten antzekotasunaren bidez definituriko kategoriak erabaki-zuhaitz probabilistikoek eta naif Bayes sailkatzaileek. Ikaskuntza ikuskatuaren adibideak dira biak ala biak; izan are, egoki sailkaturiko adibideak behar dituzte prestakuntza-datu gisa, eta irakasten zaizkien kategoriak ikasten baitituzte.
Kontrara, taldekatze-teknikak ez ditu inork berrikusten: halako teknikek baliabide kategorizatu gabeen bildumak aztertzen dituzte, eta, hala, itemen artean dauden erregulartasun edo egitura estatistikoak deskubritzen; ondorioz, kategoria-sortak sortzen dituzte, prestakuntza-datu etiketatuen beharrik gabe.
Taldekatze-teknika guztiek badute xede komun bat: kategoria esanguratsuak sortzea, abiapuntutzat harturik zuzenean hautemateko eta ebaluatzeko zailak diren ezaugarriak dituzten item-bildumak; horrek esan nahi du kategorietako kidetza ezin dela murriztu ezaugarri-proba zehatzetara, eta, horrenbestez, antzekotasunean oinarritu behar dela. Esate baterako, jarrerei dagozkien datuen sorta handi bat baldin badaukagu, taldekatze-teknikek ahalmena dute gai, genero edo iritzi beretsuak biltzen dituzten dokumentuen kategoriak edo antzeko ohiturak eta zaletasunak dituzten pertsonen kategoriak aurkitzeko.
Taldekatze-teknikek –ez baititu inork ikuskatzen– baliabideen arteko antzekotasunak kalkulatzen dituzte, eta hala sortzen dituzte kategoriak; beraz, kategoria baten barruan dauden baliabideen antzekotasuna maximizatzen dute, eta kategoria batetik bestera dagoen antzekotasuna minimizatu. Estatistikaren bidez sorturiko kategoria guzti-guztiak ez dira esanguratsuak, alegia, jendeak ezin ditu izendatu ez erabili; bestalde, antzekotasuna kalkulatzeko erabiltzen diren ezaugarrien eta metodoen hautaketak kategoria-kopuru eta -mota askotarikoak ekar ditzake. Testu-baliabideetarako taldekatze-teknika batzuek, esaterako, taldekatzeak izendatzeko izenak proposatzen dituzte, oinarritzat hartuz taldekatze bakoitzaren zentroan dauden dokumentuetako hitz garrantzitsuak. Nolanahi ere, normalean, datuen analistari edo zientzialariari egokitzen zaio deskubritu diren taldekatzeen edo gaien zentzua argitzea, salbu eta eremu berdineko baliabide-sorta etiketatu bat badago, zeinaren bidez egiazta baitaiteke ea taldekatze-teknikek kategoria berdinak deskubritu dituzten.
Distantzian oinarrituriko taldekatze-teknika ugari daude, baina denek erabiltzen dituzte hiru metodo oinarrizko.
- Batetik, taldekatze-teknika guztietan, abiapuntu gisa hartzen dira dokumentuen edo itemen sorta kategorizatu gabeak, beren arteko antzekotasuna neurtzeko moduan aurkeztuak betiere. Aurkezpen-moldea, gehien-gehienetan, ezaugarri-balioen edo hainbat ezaugarriren probabilitateen bektore bat da; hori dela-eta, itemak hainbat dimentsioko espazio batean aurkez daitezke, eta, antzekotasuna kalkulatzeko, distantzia-funtzioak erabil daitezke, 7.3.6.2 atalean deskribatu bezala –Antzekotasun-eredu geometrikoak–.
- Bigarrenik, kategoriak sortzeko, elkarren antz gehien duten itemak elkartzen dira. Taldekatzearen ikuspegi hierarkikoetan, item bakoitzak bere kategoria du. Beste ikuspegi batzuetan, hala nola K batez bestekoen taldekatzeetan, K kategorien kopuru finko batekin hasten dira, sorta osotik ausaz hautaturiko item edo dokumentu batetik abiatuz.
- Hirugarrenik, kategoria-sistema fintzen da: horretarako, kategoria batean item berri bat gehitzen den aldiro, antzekotasun iteratiboa birkalkulatzen da. Item bakoitzak bere kategoria duen ikuspegietan, kategoria-sistema hierarkiko bat sortzen da, elkarren antz gehien duten bi kategoriak uztartuz, kategoria berriaren eta geratzen diren kategorien arteko antzekotasuna berriz kalkulatuz eta prozesu hori behin eta berriz errepikatuz, harik eta kategoria guztiak kategoria bakar batean biltzen diren arte, kategoria-zuhaitzaren erroan. Ostera, kategoria-kopuru finko batekin hasten diren teknikek ez dituzte kategoria berriak sortzen; aitzitik, kategoriaren «zentroidea» birkalkulatzen dute behin eta berriro: horretarako, kide berri bat eransten den bakoitzean, ezaugarrien errepresentazioa egokitzen dute, kategoria-kide guztien batezbestekoarekin bat egiteko.
7.5.3.4 Sare neuralak
Antzekotasunaren eta probabilitatearen arabera jarduten diren sailkatzaile onenen artean, nabarmentzekoak dira sare neuralen bitartez inplementatzen direnak, eta, bereziki, ikaskuntza sakoneko teknikak baliatzen dituztenak. Ikaskuntza sakoneko algoritmoek kategoriak ikas ditzakete prestakuntza-datu etiketatuetatik abiatuz edo autokodetzea erabiliz (ikaskuntza-teknika ez-ikuskatu bat da, zeinak sare neural bat prestatzen baitu, bere input-datuak berreraiki ditzan). Dena den, datuetan zehazten diren ezaugarriak erabili ordez, ikaskuntza sakoneko algoritmoek ezaugarri-kopuru oso handi bat moldatzen dute hierarkia-geruza ezkutuetan; ondorioz, jendeak ezin ditu interpretatu. Ikaskuntza sakonaren oinarrian, ideia gako bat dago: «atzerako zabalkundea» erabiltzen da; horren bitartez, ezaugarrien garrantzia egokitzen da, outputetik (sareak sorturiko objektu-sailkapenetik) atzera eginez, inputera iritsi arte. 5.4.2 atalean azaldu dugu nola erabiltzen den ikaskuntza sakona irudiak sailkatzeko.
7.5.4 Helburuetan oinarrituriko kategoriak inplementatzea
Helburuetan oinarrituriko kategoriak indibidualizatuak dira oso, eta, maiz, behin bakarrik erabiltzen dira, testuinguru guztiz zehatz batean. Halere, komeni da gogoan izatea posible dela arauetan oinarrituriko erabaki-zuhaitzen gisara inplementatzea helburuetan oinarrituriko kategorien ereduak; hori egiteko, erabakiak antolatu beharko genituzke halako moduan non azpi-xede oro aseko dela ziurtatuko baitugu, lehentasunen arabera. «Sutan dagoen etxe batetik atera beharreko gauzak» kategoria ulertzeko, «Badago izaki bizidunik etxean?» galdera egin behar genuke lehenik, hori baita azpi-helburu garrantzitsuena. Galdera horren erantzuna «bai» baldin bada, bide bat hartuko dugu; «ez» baldin bada, ordea, beste bide bat. Era berean, lehentasun gehiago emango diegu gauza ordezkaezinei (amonaren argazkiak), ordezkagarriei baino (pasaportea).
7.5.5 Teorian oinarrituriko kategoriak inplementatzea
Zenbait eremutan, kategorizatu beharreko itemek harreman abstraktuak edo konplexuak dituzte beren ezaugarriekiko eta elkarren artean; bada, halako eremuetan azaleratzen dira teorian oinarrituriko kategoriak. Eredu horretan, ez da beharrezkoa uste izatea entitate batek berezko ezaugarri batzuk dituela, beste entitate batzuekiko komunak direnak. Aitzitik, jendeak gauza baten ezaugarriak proiektatzen ditu beste gauza batean, gauzen arteko bat-etortzeak bilatu nahian, hala nola Pyramid telebista-saioko bigarren txandako lehiakide batek beste lehiakideak emandako adibideen arteko bat-etortzeak bilatzen baitzituen, xede-kategoria asmatzeko helburuarekin. Adibidez, «garrasika ari den umea» deritzon adibideak kategoria asko iradoki ditzake, «parkimetroak» bezalaxe. Baina, haurtxoekin eta parkimetroekin, bi-biekin, zerikusia izan dezaketen kategorien harira, seguru asko «Elikatu beharreko gauzak» izango da erantzuna.
Teorian oinarrituriko kategoriak eraikuntza kognitibo gisa sortzen dira, analogiak erabiltzen ditugunean eta gauzak sailkatzen ditugunean; izan ere, gauzak analogia bidez alderatzen ditugunean, seguru asko antzekotasun abstraktua izango dute, ez literala. Analogia-prozesamenduari dagokionez, Egitura Mapak (Structure Mapping) deritzon ereduak izan du eragin handiena: Dedre Gentner-ek gidatu du horren garapena eta erabilera, eta hiru hamarkada pasatxo egin ditu langintza horretan.
Egitura Mapen baitan, hauxe da ideia nagusia: « B bezalakoa da T» dioen analogia bat sortu nahi bada, egitura erlazionalak bateratu behar dira, eta ez, ordea, oinarrizko eremuaren (B) eta xede domeinuaren (T) arteko ezaugarriak. Bi gauza hartu –berdin du zer diren–, beren baitako harreman-egiturak aztertu, eta lerrokatu egingo ditugu, bien artean zer kidetasun dagoen argitzeko. Ez da beharrezkoa bi eremuetako objektuen ezaugarriak bat etortzea; are, ezaugarri gehiegi bat etortzen baldin badira, ez da analogiarik izango, ezpada antzekotasun literala:
- Analogia: Hidrogeno-atomoak gure eguzki-sistemaren modukoak dira.
- Antzekotasun literala: X12 izar-sistema, Andromeda galaxian dagoena, gure eguzki-sistemaren modukoa da.
Edizio digitala
Lizentzia

Harremana
Iritzi, iradokizun eta ohar guztiak ongi etorriak izango dira
- aldee@aldee.eus
- 943 462 024
- Loiola Kalea, 14, 3. - 8. bulegoa
20005
Donostia